Diffusion Policy Training Visualizer
Understanding how a robot learns to pour tea using diffusion models

The Core Idea
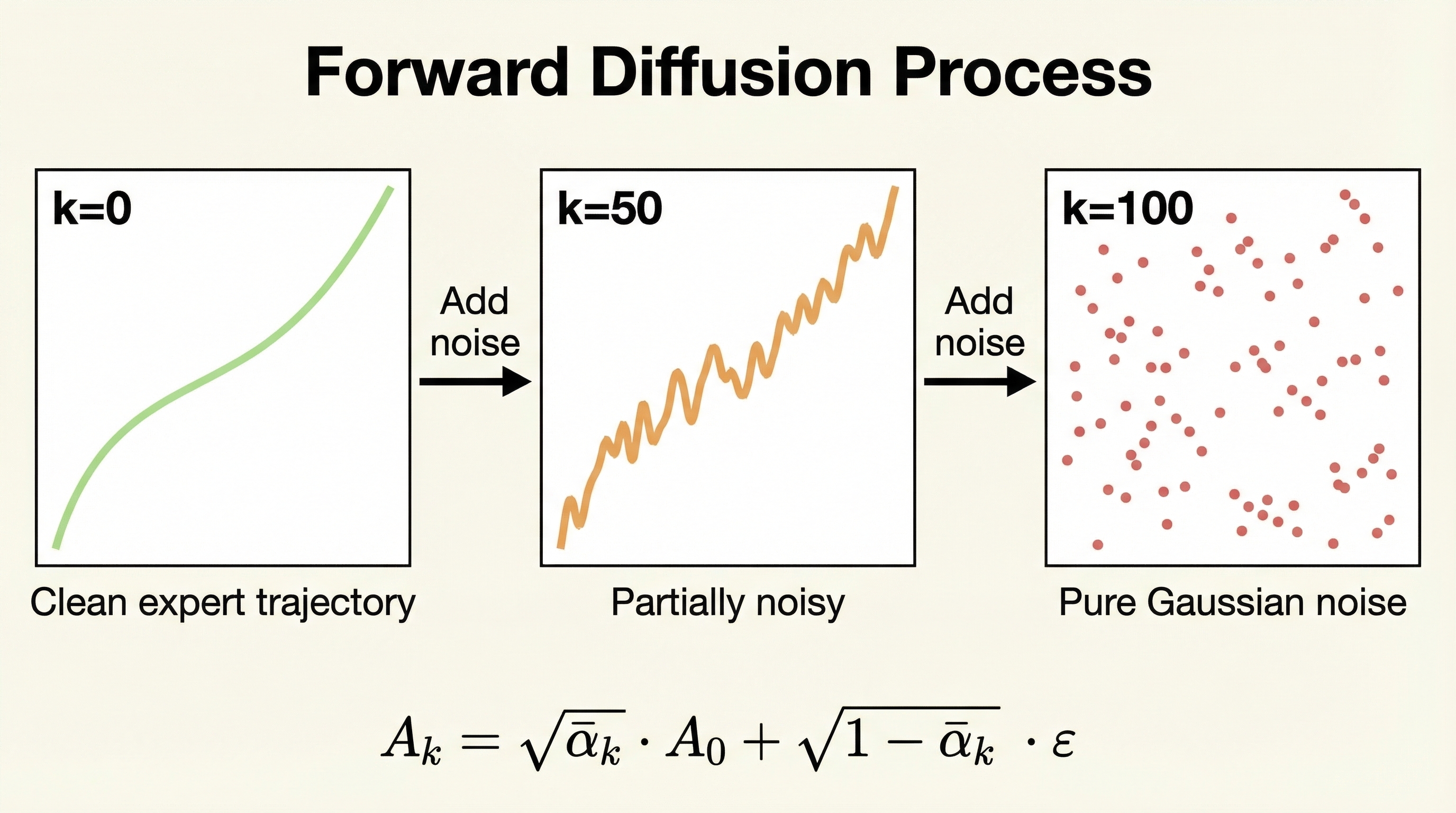
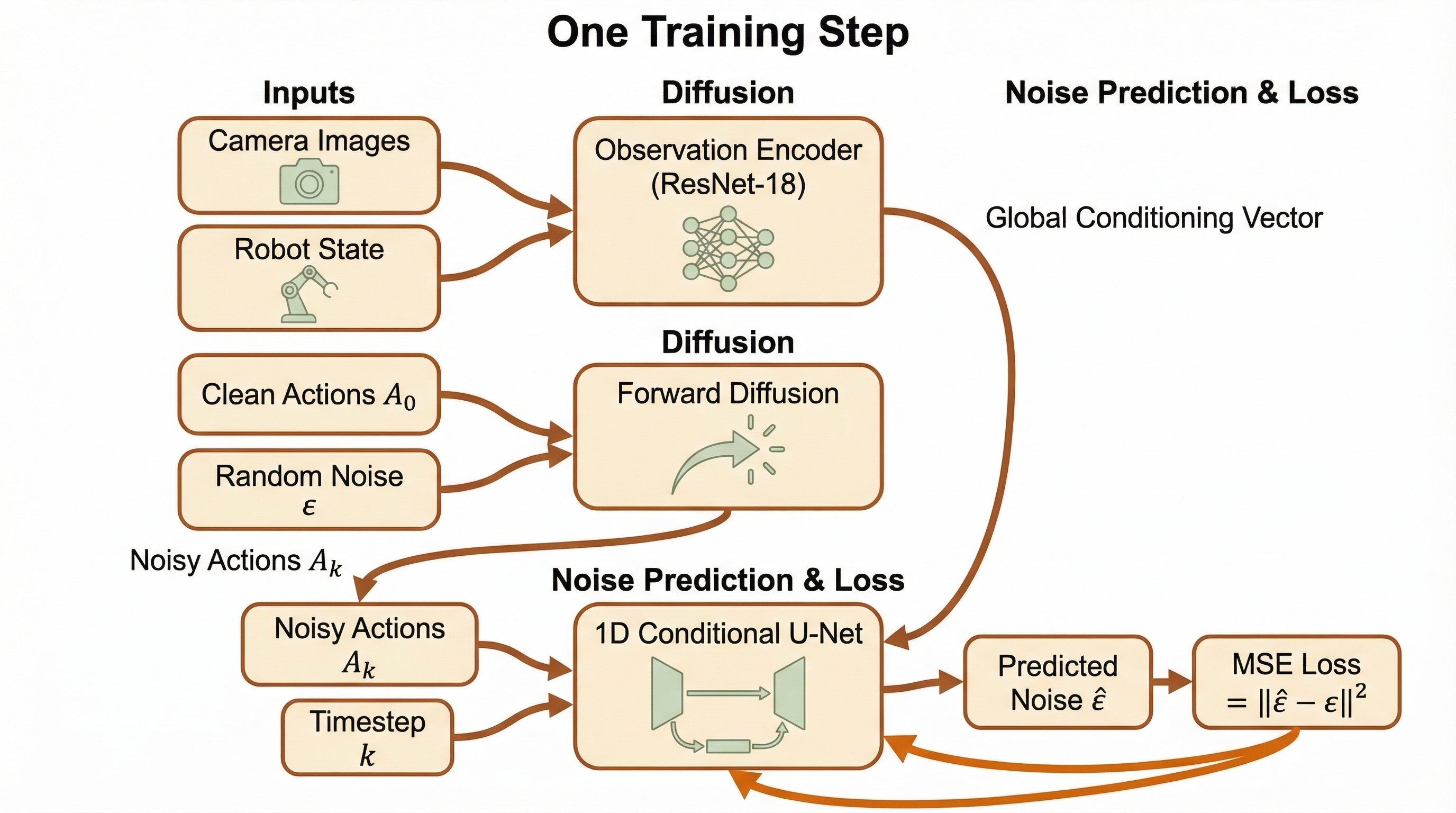
Diffusion Policy learns robot actions by treating the action trajectory (a sequence of future robot movements) as something that can be gradually corrupted with noise and then recovered by a neural network.
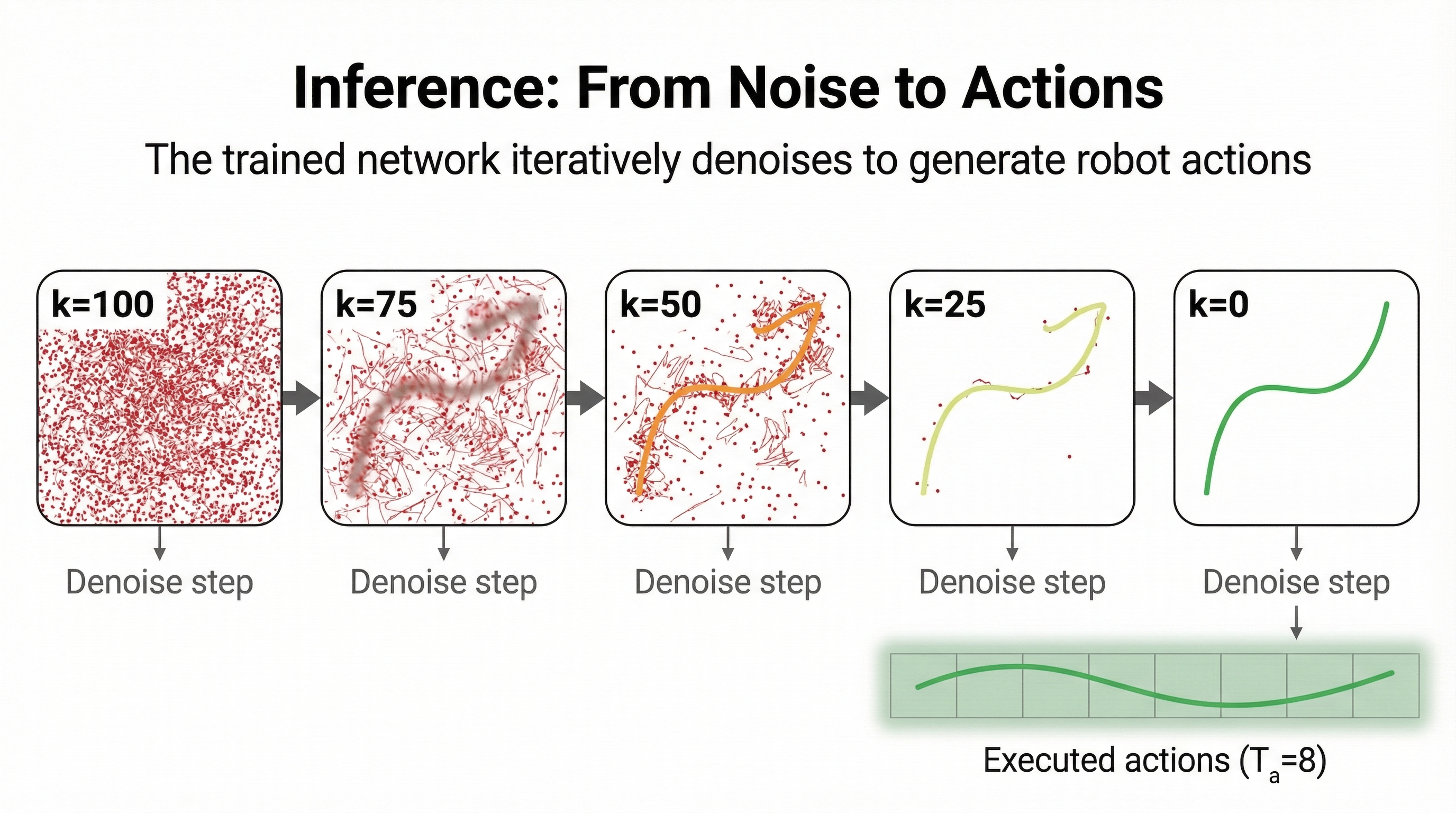
During training, we add noise to expert action trajectories and train a neural network to predict that noise. During inference, we start from pure noise and iteratively denoise to generate actions.
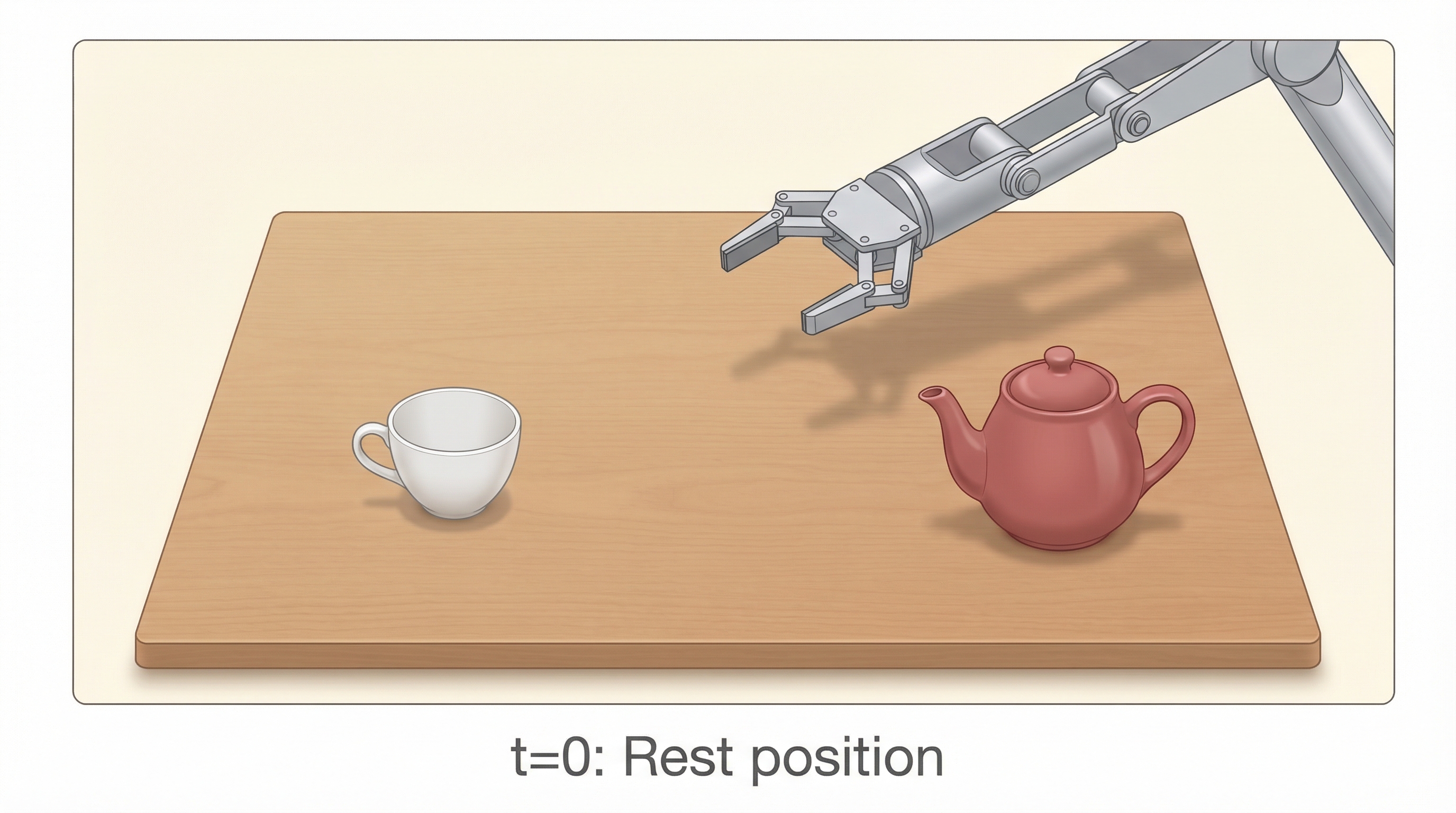
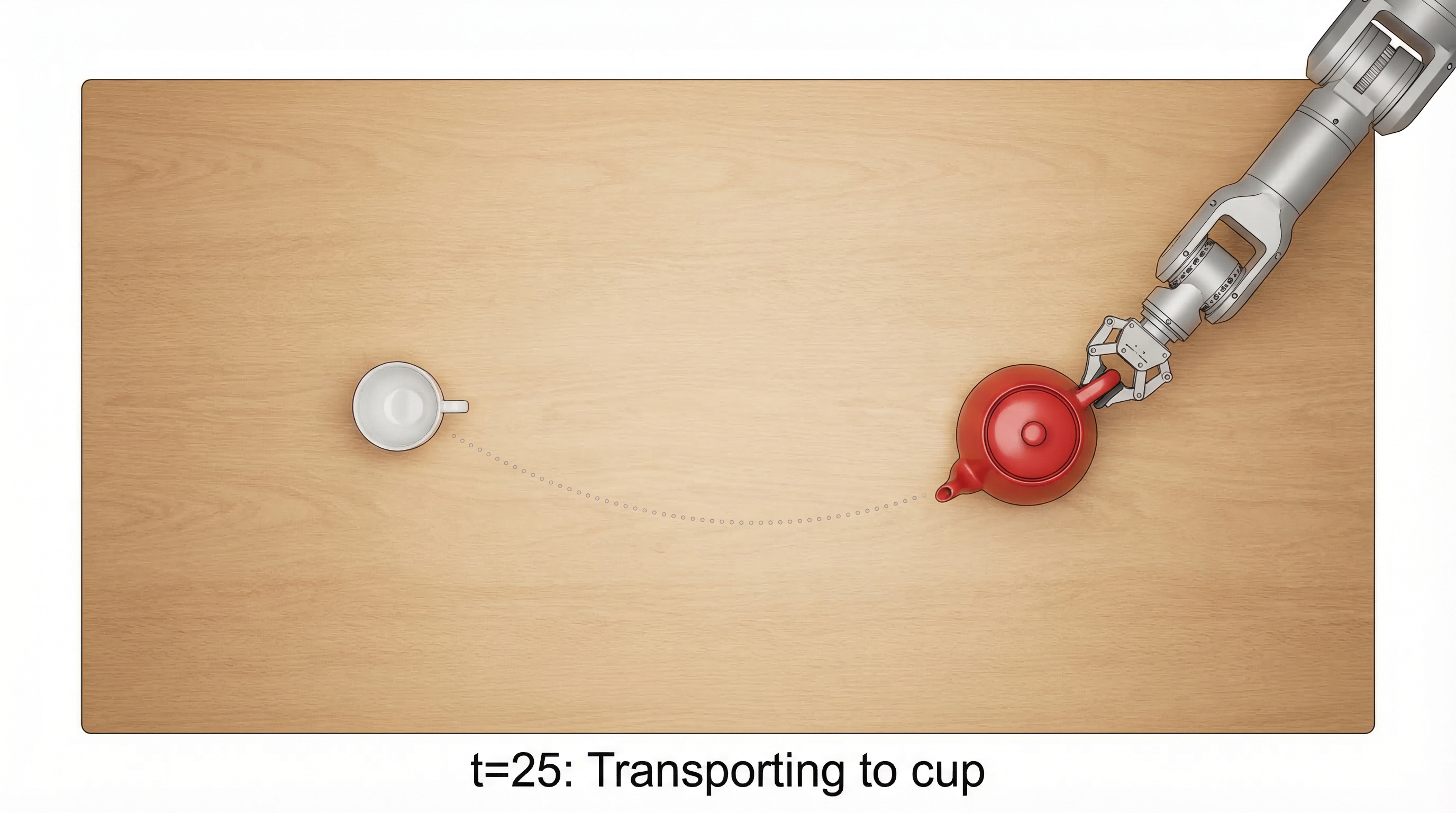
Our Example: Robot Pouring Tea
A 6-DOF robotic arm must pour tea from a teapot into a cup. We have 50 frames (5 seconds at 10 Hz) of expert demonstration data.
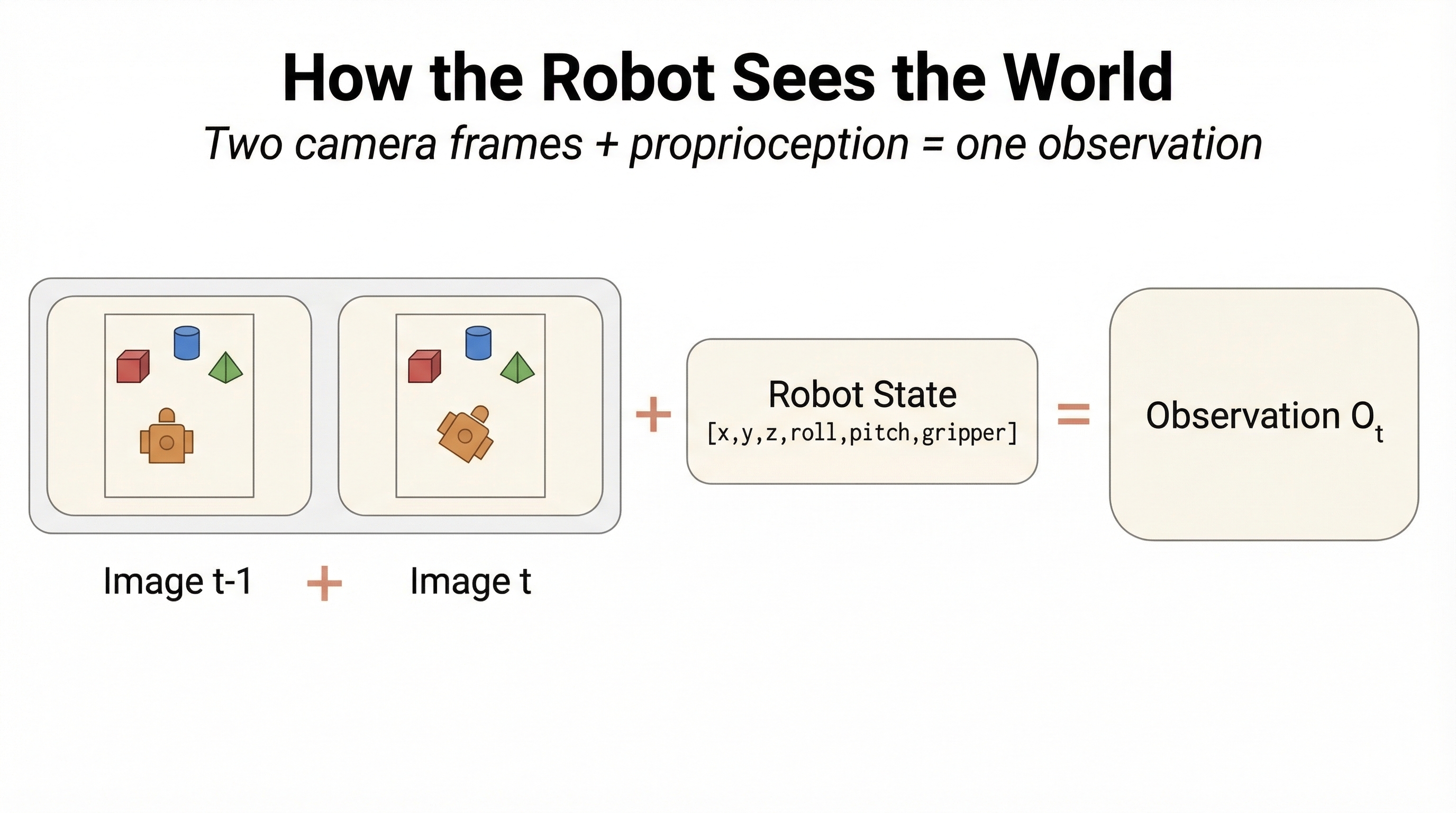
Each frame contains:
Camera Image (96x96)
Top-down view showing teapot, cup, and robot arm
Robot State (6D)
[x, y, z, roll, pitch, gripper] — joint positions
Action (6D)
[Δx, Δy, Δz, Δroll, Δpitch, Δgripper] — target deltas